transformer结构
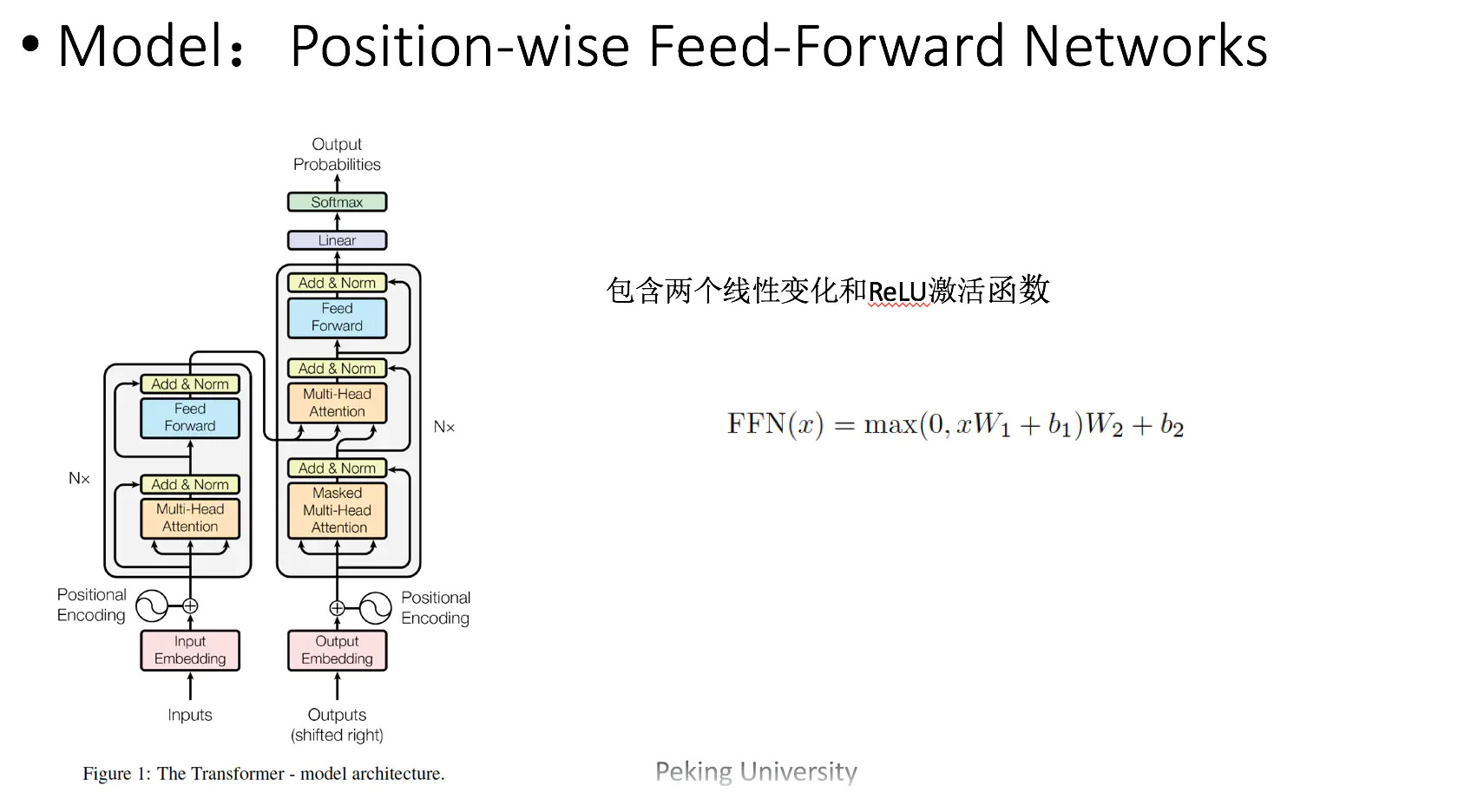
transformer 由 encoder 以及 decoder 组成
encoder
encoder 由6层完全相同的结构组成,每层包括两部分:a multi-head self-attention mechanism + positionwise fully connected feed-forward network
因为每层的输出都要进行残差连接 (residual connection) ,所以每层最后的输出为 LayerNorm(x + Sublayer(x)),维度为512
decoder
decoder 也由6层完全相同的结构组成,每层包括三部分,除了组成 encoder 的两部分外,还包含一层 a third sub-layer, which performs multi-head attention over the output of the encoder stack.
同时对 self-attention sub-layer in the decoder stack 进行了调整, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
attention
注意力函数可以说是 a query and a set of key-value pairs 到 an output 的映射,其中 the query, keys, values, and output 都是向量,output 是 values 的权重和,每个 value 的权重则是通过 query 以及相应的 key 计算得到。 (computed by a compatibility function)
Scaled Dot-Product Attention
Multi-Head Attention
self-atttention
Self-attention即K=V=Q